離散一様分布
| 確率質量関数  n = 5 ただし n = b − a + 1 | |
| 累積分布関数 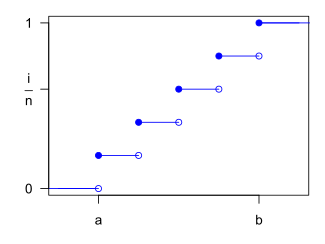 | |
| 母数 | |
|---|---|
| 台 | |
| 確率質量関数 | |
| 累積分布関数 | |
| 期待値 | |
| 中央値 | |
| 最頻値 | N/A |
| 分散 | |
| 歪度 | |
| 尖度 | |
| エントロピー | |
| モーメント母関数 | |
| 特性関数 | |
| テンプレートを表示 | |













離散一様分布(りさんいちようぶんぷ、英: discrete uniform distribution)は、確率論や統計学における離散確率分布の一種であり、有限集合の全ての値について、等しく確からしい場合である。
確率変数が n 個の値 k1, k2, …, kn を同じ確率でとりうるとき、離散一様分布と言える。任意の ki の確率は 1/n である。離散一様分布の単純な例としてサイコロがある。その場合の k がとりうる値は 1, 2, 3, 4, 5, 6 で、1回サイコロを振ったとき、それぞれの値が出る確率は 1/6 である。2個のサイコロを振って和をとると、もはや一様分布ではなくなり、とりうる値(2 から 12)によって確率が変わってくる。
離散一様分布の確率変数がとりうる値が実数の場合、累積分布関数を退化分布を使って表すことができる。すなわち、

ここで、ヘヴィサイドの階段関数 は、x0 を中心とする退化分布の累積分布関数である。この式は、各転移点で一貫した規定が使われると想定している。

非復元抽出による最大値の推定
整数 1, 2, …, N から k 個の標本が非復元抽出され、離散一様分布と同様に、標本の抽出のされ方に整数による差はないとする。ここで未知の最大値 N を推定する問題が生じる。このような問題を一般に German tank problem(ドイツ戦車問題)と呼び、第二次世界大戦中のドイツでの戦車生産数の最大値を推定するという問題に由来する。
最大値のUMVU推定によると、次のようになる。

ここで m は標本内の最大値、k は標本数である[1][2]。これは maximum spacing estimation の非常に単純な例と見ることもできる。
この式は直観的に次のように理解できる。
- 「標本の最大値に観測された標本値の平均間隔を加える」
この間隔は標本の最大値の負のバイアスを補填するよう加算され、母集団の最大値の推定とする[notes 1]。
この分散は次のようになる[1]。

つまり標準偏差は約 N/k で(母集団の)標本間の間隔の平均であり、上の m/k に似ている。
標本の最大値は母集団の最大値の最尤推定量だが、これまで述べたようにバイアスがかかっている。
標本が数として捉えられず、単に識別可能あるいは標識を付与できるなら、母集団の大きさの推定を標識再捕獲法で行うことができる。
関連項目
- ディラックのデルタ関数
- 連続一様分布
- ドイツ戦車問題(英語版) - 第二次世界大戦中にドイツ側の戦車の生産台数を計算から割り出していた。
脚注
- ^ 標本の最大値は母集団の最大値を超えることは決してないが、小さくなることはありうる。したがって、バイアスのある推定値である。母集団の最大値は小さく推定される傾向がある。
出典
- ^ a b Johnson, Roger (1994), “Estimating the Size of a Population”, Teaching Statistics 16 (2 (Summer)), doi:10.1111/j.1467-9639.1994.tb00688.x
- ^ Johnson, Roger (2006), “Estimating the Size of a Population”, Getting the Best from Teaching Statistics, http://www.rsscse.org.uk/ts/gtb/johnson.pdf
| |
|---|---|
| 離散単変量で 有限台 | |
| 離散単変量で 無限台 | |
| 連続単変量で 有界区間に台を持つ | |
| 連続単変量で 半無限区間に台を持つ |
|
| 連続単変量で 実数直線全体に台を持つ | |
| 連続単変量で タイプの変わる台を持つ | |
| 混連続-離散単変量 |
|
| 多変量 (結合) | |
| 方向 |
|
| 退化と特異 |
|
| 族 |
|
| サンプリング法(英語版) |
|
| |








