Rozdělení pravděpodobnosti
Rozdělení pravděpodobnosti (někdy také distribuce pravděpodobnosti) náhodné veličiny je pravidlo, kterým se každému jevu popisovanému touto veličinou přiřazuje určitá pravděpodobnost. Rozdělení pravděpodobnosti náhodné veličiny vznikne, pokud je každé hodnotě diskrétní náhodné veličiny nebo intervalu hodnot spojité náhodné veličiny přiřazena pravděpodobnost.
Rozdělení pravděpodobnosti lze také chápat jako zobrazení, které každému elementárnímu jevu přiřazuje určité reálné číslo, které charakterizuje pravděpodobnost tohoto jevu.
Rozdělení pravděpodobnosti diskrétní náhodné veličiny
Pravděpodobnost, že diskrétní náhodná veličina bude mít po provedení náhodného pokusu hodnotu , značíme , nebo stručně .



![{\displaystyle P[X=x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5679b8223b3f4cfc7de60a662d47cff5bc2d961e)

Výsledkem jednoho náhodného pokusu je to, že náhodná veličina bude mít právě jednu hodnotu. Všechny hodnoty definičního oboru náhodné veličiny tedy představují úplný systém neslučitelných jevů, což znamená, že součet pravděpodobností všech možných hodnot diskrétní náhodné proměnné je roven 1, tzn.
![{\displaystyle \sum _{x}P[X=x]=1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98f5dbc58e7f632e0606638619cbd4013fc753df)
Pravděpodobnostní funkce
Rozdělení pravděpodobnosti diskrétní náhodné veličiny se tedy vyjádří tak, že se určí pravděpodobnost pro všechna definičního oboru veličiny . Pravděpodobnosti jednotlivých hodnot jsou tedy vyjádřeny funkcí , která se nazývá pravděpodobnostní funkce.

Hodnoty pravděpodobností funkce vyjadřujeme obvykle tabulkou, např.
| x | P(x) |
| … | … |






Také se používá vyjádření ve formě grafu (viz obrázek). V některých případech lze také použít vyjádření pomocí matematického vzorce.
Znalost pravděpodobnostní funkce lze použít k výpočtu pravděpodobnosti. Například pravděpodobnost, že náhodná veličina leží mezi hodnotami a , se určí jako
![{\displaystyle P[x_{1}\leq X\leq x_{2}]=\sum _{x=x_{1}}^{x_{2}}P(x)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2c0f79a1d0b9036d64176082c5959caf4cbc2fc)
Distribuční funkce diskrétní veličiny
Pomocí pravděpodobnostní funkce lze zavést distribuční funkci vztahem
![{\displaystyle F(x)=P[X\leq x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6dc4ea19dbd1d678eef1a2e2a3aeb8044c29081b)
Distribuční funkce je neklesající a je spojitá zprava. Hodnoty distribuční funkce leží v rozsahu . Pro diskrétní náhodnou veličinu lze pro libovolné reálné číslo vyjádřit distribuční funkci vztahem


Vlastnosti
Jestliže hodnoty náhodné veličiny leží v intervalu , pak a .



Distribuční funkci lze, podobně jako pravděpodobnostní funkci, použít k výpočtu pravděpodobnosti, neboť
![{\displaystyle P[x_{1}<X\leq x_{2}]=F(x_{2})-F(x_{1})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfbcbbfd6230d6cadd5165776047a9b305029b24)
Důležitá diskrétní rozdělení
- Alternativní rozdělení (X nabývá pouze dvou hodnot 0 nebo 1)
- Binomické rozdělení (n pokusů se stejnou pravděpodobností)
- Poissonovo rozdělení
- Negativně binomické rozdělení
- Pascalovo rozdělení (speciální případ negativně binomického rozdělení)
- Geometrické rozdělení (speciální případ Pascalova rozdělení)
- Hypergeometrické rozdělení
- Logaritmické rozdělení
Rozdělení pravděpodobnosti spojité náhodné veličiny
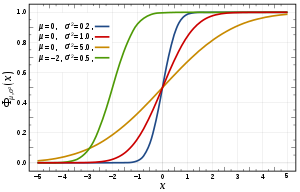
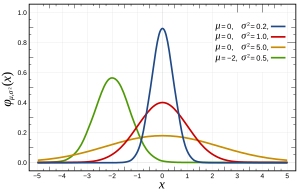
Spojitá náhodná veličina má spojitou distribuční funkci . Rozdělení spojité náhodné veličiny nelze popsat pravděpodobnostní funkcí v určitém bodě.

Hustota pravděpodobnosti
Podrobnější informace naleznete v článku Hustota pravděpodobnosti.
Hustota pravděpodobnosti je funkce, jejíž hodnotu pro libovolný zvolený prvek z množiny možných vzorků (hodnot náhodné proměnné) lze interpretovat jako relativní četnost hodnoty tohoto prvku v rámci celé množiny možných vzorků daného času.
Rozdělení pravděpodobnosti spojité náhodné veličiny se určuje prostřednictvím funkce, která se nazývá hustota rozdělení pravděpodobnosti (hustota pravděpodobnosti, anglicky Probability Density Function, PDF). Pro spojitou náhodnou veličinu obecně neplatí, že také hustota pravděpodobnosti je spojitá.
Je-li hustota pravděpodobnosti spojité náhodné veličiny , pak platí

- ,

kde je definiční obor veličiny . Pro hodnoty mimo definiční obor je hustota pravděpodobnosti nulová, takže pro .



Ze znalosti hustoty pravděpodobnosti je možné určit pravděpodobnost, že náhodná veličina nabývá hodnotu z intervalu , tedy

![{\displaystyle P[x_{1}\leq X\leq x_{2}]=\int _{x_{1}}^{x_{2}}\rho (x)\mathrm {d} x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/285e5c69790c2f62a35a0ac0b363f599ba5c656b)
Pravděpodobnost, že spojitá náhodná veličina nabývá určité (přesně dané) hodnoty, je nulová, což plyne z předchozího vztahu. Důsledkem toho je, že pro spojitou náhodnou veličinu platí vztahy
![{\displaystyle P[x_{1}\leq X\leq x_{2}]=P[x_{1}<X\leq x_{2}]=P[x_{1}\leq X<x_{2}]=P[x_{1}<X<x_{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44b0be7d01fc08fba37d005bf27397ec34cc72f6)
Distribuční funkce spojité veličiny
Distribuční funkce jednorozměrné reálné náhodné veličiny se definuje jako pravděpodobnost, že realizace této náhodné veličiny nepřekročí :
Distribuční funkce je neklesající, zprava spojitá, její limita je nula, v pak jedna.


Komplementární distribuční funkce se pak definuje jako .

Pro spojitou náhodnou veličinu s hustotou pravděpodobnosti se distribuční funkce dá spočítat také podle vztahu

Vlastnosti
Platí, že a .


Distribuční funkci lze použít k výpočtu pravděpodobnosti, neboť
![{\displaystyle P[x_{1}\leq X\leq x_{2}]=F(x_{2})-F(x_{1})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/67a14f282f41d1ebc3b69d06655cc02d41456950)
Lze dokázat, že mezi hustotou pravděpodobnosti a distribuční funkcí platí vztah
- ,

pokud derivace distribuční funkce v daném bodě existuje.
Důležitá spojitá rozdělení
- Rovnoměrné rozdělení
- Normální rozdělení (označované také jako Gaussovo rozdělení)
- Logaritmicko-normální rozdělení (také log-normální rozdělení)
- Exponenciální rozdělení
- Cauchyho rozdělení
- Gama rozdělení
- Laplaceovo rozdělení (nebo také dvojitě exponenciální rozdělení)
- Logistické rozdělení
- Maxwellovo–Boltzmannovo rozdělení
- Studentovo rozdělení
- Fisherovo–Snedecorovo rozdělení
- χ² rozdělení (Chí kvadrát)
- rozdělení beta
Vícerozměrné rozdělení pravděpodobnosti
Sdružená a marginální pravděpodobnost
Mějme -rozměrný náhodný vektor , jehož složkami jsou diskrétní náhodné veličiny . Jejich rozdělení lze popsat sdruženou (simultánní) pravděpodobností



![{\displaystyle P(\mathrm {x} )=P(x_{1},x_{2},...,x_{n})=P[X_{1}=x_{1}\cap X_{2}=x_{2}\cap \cdots \cap X_{n}=x_{n}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb409bd7bd5d8a1249fb4499f018a56921eb5f7a)
Tento vztah udává pravděpodobnost, že náhodná veličina nabude hodnotu , náhodná veličina nabude hodnoty , atd. pro všechna a .



Pro sdružené pravděpodobnosti zobrazují v korelační tabulce

| x | … | Součet | |||
| … | |||||
| … | |||||
| … | … | … | … | … | … |
| … | |||||
| Součet | … | 1 |



















Pravděpodobnosti a jsou marginální (okrajové) pravděpodobnosti. Platí tedy




Dále platí

Sdružená a marginální distribuční funkce
Sdruženou (simultánní) distribuční funkci lze pro -rozměrný náhodný vektor diskrétních veličin definovat jako

Sdružená distribuční funkce (pro dvě proměnné X, Y) splňuje podmínky


Podobné podmínky platí také pro vícerozměrné náhodné vektory.
Marginální (okrajové) distribuční funkce lze pro vektor dvou proměnných a zapsat vztahy



Podobně lze marginální distribuční funkce určit také v případě vícerozměrných náhodných vektorů.
Sdružená a marginální hustota pravděpodobnosti
Rozdělení dvou spojitých náhodných veličin je možné popsat sdruženou hustotou pravděpodobnosti . Sdružená hustota pravděpodobnosti musí splňovat podmínku

![{\displaystyle \int _{\Omega }\left[\int _{\Omega }f(x,y)\mathrm {d} x\right]\mathrm {d} y=1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/292bea090f54bcd719d736b581b2bc0ad0c48283)
Marginální hustoty pravděpodobnosti se určí jako


Sdruženou distribuční funkci pak je
![{\displaystyle F(x,y)=\int _{-\infty }^{x}\left[\int _{-\infty }^{y}f(t,u)\mathrm {d} t\right]\mathrm {d} u}](https://wikimedia.org/api/rest_v1/media/math/render/svg/706095ca349bfaba79aa896fab0060c246ea5e02)
Ze sdružené distribuční funkce lze naopak získat sdruženou hustotu pravděpodobnosti

Podobně lze postupovat také v případě -rozměrných vektorů spojitých náhodných veličin. Sdruženou hustotu pravděpodobnosti je pak možné získat jako

Marginální pravděpodobnost lze definovat pro libovolnou skupinu veličin () daného -rozměrného náhodného vektoru. Rozdělení je závislé pouze na daných veličinách a na zbývajících veličinách nezávisí. Pro je nutno rozlišovat podvojnou nezávislost a nezávislost vzájemnou.




Jsou-li veličiny vzájemně nezávislé, pak platí



Podmíněné rozdělení pravděpodobnosti
Podmíněné rozdělení náhodné veličiny vzhledem k veličině je rozdělení veličiny za podmínky, že náhodná veličina nabyla hodnoty .

Podmíněné rozdělení je definováno jako podíl rozdělení sdruženého a marginálního.
Pro dvě diskrétní náhodné veličiny je možné podmíněnou pravděpodobnost veličiny vzhledem k zapsat jako


pro , kde je marginální pravděpodobnost a je pravděpodobnost sdružená.



Obdobně vznikne pro podmíněnou pravděpodobnost veličiny vzhledem k vztah

pro , kde je marginální pravděpodobnost a je opět sdružená pravděpodobnost.


Podmíněná distribuční funkce
Podmíněné distribuční funkce zapsat zapsat jako


Podmíněná hustota pravděpodobnosti
U dvourozměrného náhodného vektoru, jehož složkami jsou spojité náhodné veličiny a , lze podmíněné hustoty pravděpodobnosti vyjádřit jako

pro a


pro , kde je sdružená hustota pravděpodobnosti a a jsou marginální hustoty pravděpodobnosti.



Pro podmíněné distribuční funkce spojitých náhodných veličin pak platí


Charakteristiky rozdělení náhodné veličiny
Související informace naleznete také v článku Charakteristika náhodné veličiny.
Charakteristiky náhodné veličiny jsou vhodně vybrané číselné údaje, které shrnují základní informace o rozdělení pravděpodobnosti náhodné veličiny. Charakteristiky poskytují pouze základní a hrubou představu o náhodné veličině, neboť charakteristiky (obvykle) nepostačují k jednoznačnému popisu rozdělení pravděpodobnosti. Naproti tomu rozdělení pravděpodobnosti sice poskytuje jednoznačný popis náhodné veličiny, obvykle však není dostatečně přehledné.
Důležitými charakteristikami rozdělení jsou střední hodnota a rozptyl.
Literatura
- HAMPL, Martin. Realita, společnost a geografická organizace: hledání integrálního řádu. Praha : DemoArt, 1998. ISBN 80-902154-7-5
Související články
Externí odkazy
 Obrázky, zvuky či videa k tématu rozdělení pravděpodobnosti na Wikimedia Commons
Obrázky, zvuky či videa k tématu rozdělení pravděpodobnosti na Wikimedia Commons
Portály: Matematika







